Entrevista técnica para desarrollador microservicios | Preguntas y respuestas (II)

En la entrada anterior, realizamos una primera parte de la serie de preguntas y respuestas comunes que suelen hacerse en las entrevistas de trabajo para aplicar por un puesto como desarrollador en un área enfocada en los microservicios. También disponible en nuestro canal de Youtube por si te aburre leer :-).
En esta entrada seguiremos la serie y veremos 5 posibles preguntas más y sus respuestas.
Si deseas leer debajo está el artículo textual, si prefieres vídeo acá lo tienes:
Explique cómo funciona un servicio de registro y descubrimiento así como su importancia para la infraestructura.
En la arquitectura microservicios los pequeños servicios están distribuidos en diversos nodos y/o contenedores, un servicio a su vez puede tener múltiples instancias dispersas en la red de igual forma, por ejemplo:

Es común además que en la arquitectura microservicios existan servicios que consuman otros servicios, supongamos ahora que en este mismo ejemplo tenemos un servicio de ordenes que para Crear una orden requieren tomar uno o varios elementos del menú y ejecutar un pago posteriormente. El escenario sería así:
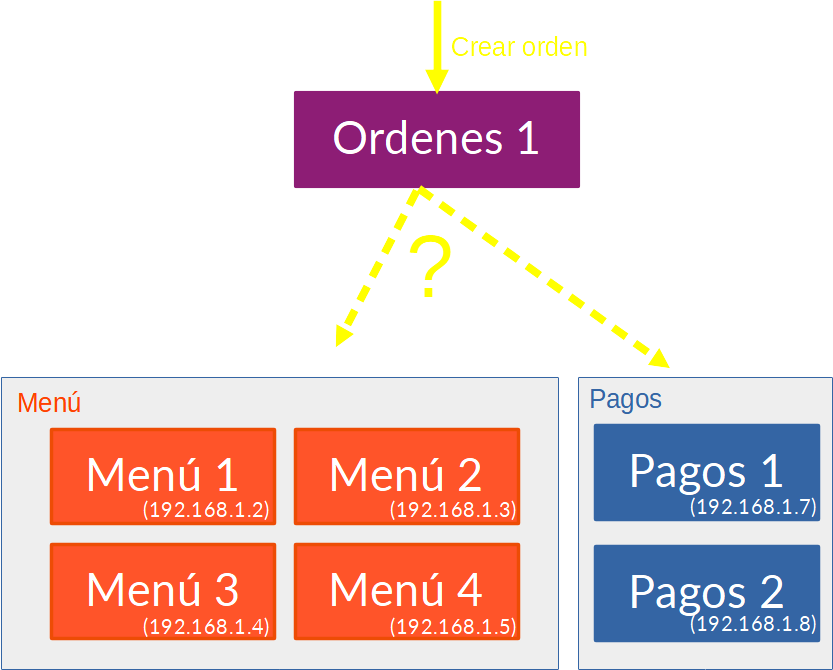
En este escenario como sabe el microservicio de Ordenes 1 a que dirección debe dirigir su solicitud, tengamos en cuenta que las instancias de Menú y Pagos son dinámicas y que en este momento pueden haber 4 instancias de menú porque hay demanda pero dentro de una hora quizás exista una sola operativa.
Es este el problema que resuelve el servicio de registro y descubrimiento. Te recomiendo si deseas aprender más sobre este patrón las siguientes entradas:
La importancia en resumen:
- Permite registrar y conocer la ubicación de las instancias activas de la infraestructura.
- Permite saber el estado de las instancias (UP/DOWN).
- Permite el trabajo al balanceador de cargas.
- Facilita al API Gateway el poder operar a nivel de identificadores de microservicios y evitar ruteo estático.
Para complementar la respuesta se puede mencionar que existen dos formas de implementar un service discovery (del lado cliente y del lado del servidor), y la existencia de soluciones técnicas que implementan este patrón como Netflix Eureka.
En una arquitectura microservicios la escalabilidad es una característica deseada, como resultado de su aplicación pueden estar operativas múltiples instancias de varios microservicios. Suponga que una instancia del microservicio A debe llamar a otra instancia del microservicio B ¿Qué técnica o estrategias serían correctas seguir para que la instancia de A llame a una instancia “adecuada” de B ?
Esta pregunta es similar a la anterior, pero va un poco más allá, porque además de evaluarnos como una instancia A puede saber donde está una instancia B, nos desean evaluar cómo podemos llegar a la instancia B más adecuada. El término de “adecuada” viene de la mano de dar una respuesta más óptima / en el menor tiempo posible.
Si bien con la respuesta de la pregunta anterior podemos saber a que microservicio llegar, no hemos definido o aplicado alguna estrategia que nos permita ir a la instancia más adecuada. Para resolver este problema debemos implementar un balanceador de cargas.
En términos simples un balanceador de cargas permite encaminar los requests de A a B de forma tal que lleguen a una instancia de B siguiendo una estrategia de balanceo. Algunas de las estrategias de balanceo posibles, que permiten llegar al microservicios más adecuados (con menos carga o más cercanos) son:
- Round Robin: Va repartiendo las solicitudes que llegan a B por cada una de las instancias de B disponibles y activas.
- Round Robin ponderado: Las solicitudes se asignan a las instancias de B de acuerdo a una ponderación que tienen los nodos/contenedores de las instancias, acorde generalmente a la carga que pueden soportar.
- Posición geográfica: Las solicitudes se asignan a las instancias más cercanas al origen de la misma. Por ejemplo si la solicitud se origina en Japón y existe alguna instancia desplegada en la región de Osaka de AWS, entonces se asigna a la instancia de dicha región.
Te recomiendo veas el vídeo: Balanceador de cargas en microservicios, en nuestro canal de Youtube.
La interacción de los servicios de la infraestructura con componentes externos (llamemos legacy) tiene lugar en muchos escenarios. Es común que los sistemas legacy estén desarrollados con tecnologías obsoletas o poco eficientes. ¿Qué solución técnica podría aplicarse para evitar implementar en los microservicios código específico demasiado atado al sistema legacy?
La pregunta viene dada porque es común que en una arquitectura microservicios algunos de los pequeños servicios tengan que interactuar con servicios externos, por ejemplo imaginemos estamos en el contexto financiero de un sistema de restaurantes y los microservicios de Pagos y Fraude tienen que conectar en algún momento con sistemas como KYC, Exchange Rate API y Bank System, los sistemas con los que debemos interactuar permiten los protocolos/mecanismos de intercambio SOAP/XML, Socket sobre TCP/IP y Corba respectivamente.
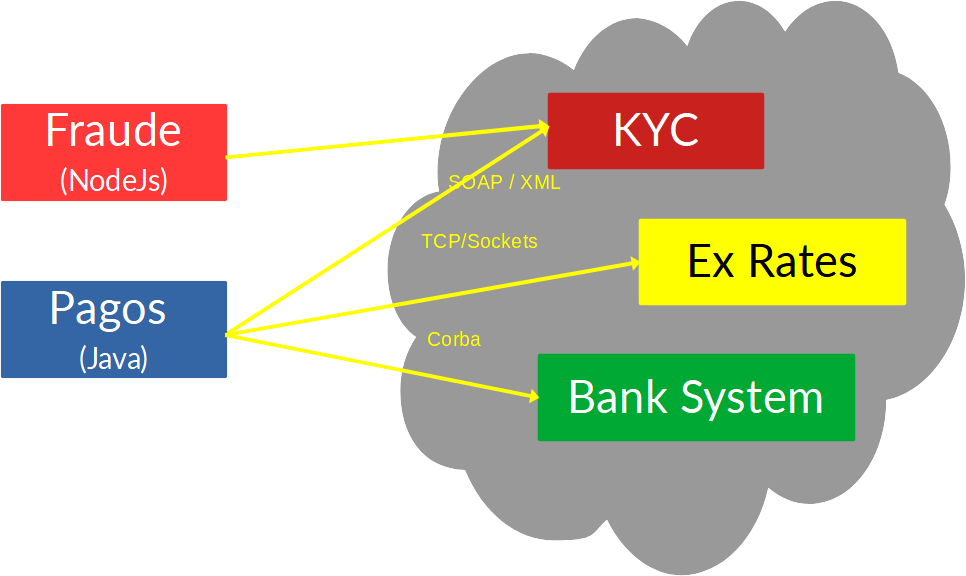
Entonces, el problema radica en que no está bueno llevar esas tecnologías legacy a los servicios de la plataforma, pues puede complejizar su mantenibilidad o crear puntos de fallas en varios lugares ante problemas externos. Incluso puede darse el caso de que algún lenguaje particular de los usados en los servicios de la arquitectura no soporte esos protocolos de comunicación.
Llegado a este punto, la solución técnica o patrón que resuelve este problema es Capa anticorrupción, una capa anticorrupción propone crear un servicio (o varios) que se encargue de interactuar con los sistemas externos necesarios. En este caso, por ejemplo creemos un “Financial Broker”.
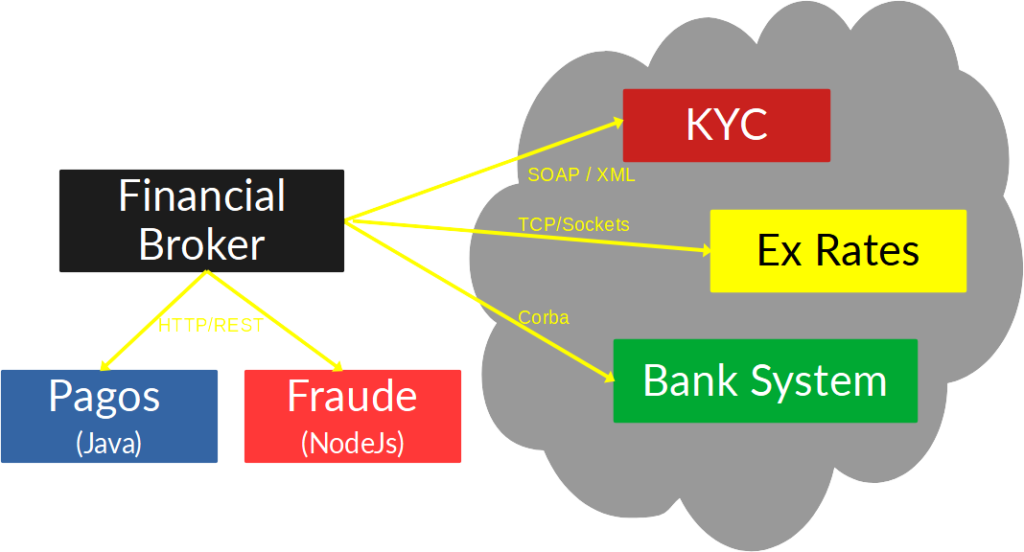
Sería interesante responder en esta pregunta además para mostrar más completitud en la respuesta algunas consideraciones importantes que hay que tener a la hora de crear una capa anticorrupción:
- La capa anticorrupción puede añadir latencia a las llamadas entre sistemas.
- Si el flujo de llamadas es alto, deben tenerse en cuenta mecanismos de escalabilidad en la capa y balanceo de carga entre múltiples instancias.
- La capa anticorrupción tendrá (probablemente) mecanismos de traducción de protocolos.
Puedes leer más en nuestro artículo sobre Capa anticorrupción.
Explique cómo funciona Bulkhead y su relación con la resiliencia
La respuesta a esta pregunta puede verla en este artículo. Y una explicación más amplia en nuestro canal de Youtube.
¿Qué es la transaccionalidad distribuida y que relación tiene con los microservicios?
La respuesta a esta pregunta puede verla en los siguientes artículos, principalmente en la Parte I.
Y una explicación más amplia en nuestro canal de Youtube.
Espero que te haya gustado esta entrada, nos vemos en la tercera entrada.




