Patrón: Métricas de rendimiento en la observabilidad de los microservicios

La distribución de los microservicios en diferentes nodos, y la necesidad de poder contar con información que permita conocer el estado de los mismos para poder tomar decisiones y verificar métricas específicas del negocio, da lugar a la aplicación del patrón métricas de rendimiento.
A la aplicación de esta práctica, la documentación se refiere como APM (Application Performance Monitoring), en español monitoreo del rendimiento de las aplicaciones.
Te ayudamos a ser un mejor desarrollador backend.
La bibliografía en ocasiones también expresa que APM es solo una parte de métricas de rendimiento. En este artículo hablamos de APM con Spring, Micrometer, Prometheus y Grafana. En el libro de Patrones para la implementación de una arquitectura microservicios, hablamos más temas de observabilidad en la arquitectura por si quieres conocer más.
La siguiente figura muestra la arquitectura general de un sistema de recolección de métricas.
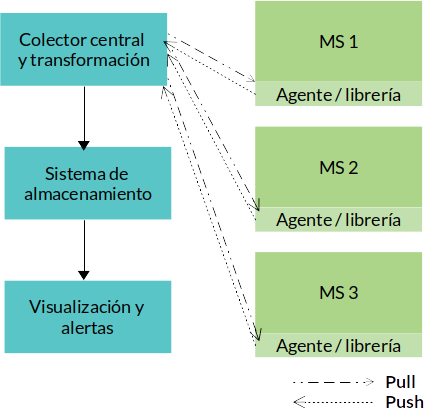
Las métricas permiten desde el punto de vista numérico ver el rendimiento de determinados aspectos, generalmente en las aplicaciones se evalúan dos grupos de métricas importantes:
- Desempeño del software (APM puramente): Nos permiten monitorear y dar seguimiento a indicadores asociados al rendimiento de los microservicios. Vale la pena monitorear elementos como consumo de CPU, memoria RAM, espacio en disco, parámetros de uso de la red, tiempos de escritura/lectura, cantidad de operaciones procesadas (conocido como throughput) y muchos otros indicadores.
- KPI: Este grupo de métricas están centradas en el negocio y permiten conocer los indicadores claves de desempeño (key performance indicators), por ejemplo, en una aplicación de restaurantes la cantidad de pedidos por unidad de tiempo, grado de usuarios satisfechos, nivel de conversión, y todos aquellos que se definan y se implementen los mecanismos para medirlos.
Los parámetros más comunes que se monitorean (en APM) son:
- Errores de aplicación.
- Tiempos de respuesta.
- Consultas a bases de datos.
- Estado del pool de conexiones a las bases de datos.
- Experiencia del usuario (en dependencia de si hay interacción).
- Verificación de los parámetros de JVM para aplicaciones que se ejecutan en ella (estado de las zonas de memoria, recolector de basura, entre otros).
En la infraestructura, al poder tener diversos grados de segregación se recomienda monitorear a 3 niveles:
- Nodos: Es el entorno en el que corren contenedores o aplicaciones desplegadas directamente. Debemos monitorear uso de CPU, memoria, red, disco y sistema de archivos. Las métricas del sistema ayudan a comprender la asignación de recursos para cada nodo y a solucionar problemas ante valores atípicos.
- Contenedor: Deben recopilarse las métricas a nivel de contenedor y de la máquina virtual.
- Servicio: Se debe recopilar información del rendimiento de la aplicación, en dependencia de la tecnología varían los datos (y su nivel de detalle). La información asociada a los KPI, bien puede ser obtenida por análisis de datos de la(s) persistencia(s) del sistema o por implementar ciertos medidores que al pasar ciertos puntos de la aplicación notifiquen el cumplimiento del KPI e ir emitiendo en tiempo real al sistema de métricas.
Pull / Push
La recopilación de métricas puede hacerse siguiendo dos principios:
- Pull: En esta variante el agente que recolecta las métricas “solicita” la información que necesita recuperar y la inserta en el sistema de almacenamiento.
- Push: El servicio (o agente encargado de su monitoreo) envía hacia un destino la información usando la tecnología en dependencia del receptor (cola de mensajes, llamada a un API, tcp, entre otros). Para el monitoreo de nodos y contenedores, habitualmente se usa un agente que recolecta las métricas.
Independiente al método de recopilación que se emplee, la mayoría (para no se ser absolutos) de los sistemas emplean “sistemas de series de tiempo” para marcar el momento en que graban la información recopilada.
¿Cuándo usar este patrón?
La recopilación de métricas y el monitoreo no es una opción en la arquitectura basada en microservicios, siempre debe ser llevada a cabo.
Software recomendado
Muy variadas son las posibles soluciones que existen:
- ELK (ElasticSearch, Logstash, Kibana), incluye en el stack opciones para observabilidad muy completas.
- TIG (Telegraf, InfluxDB, Grafana).
- Prometheus.
- Micrometer para la recuperación de métricas con soporte para ofrecer los datos a múltiples proveedores.
- Privativas y de pago como Dynatrace o New Relic.
Existen otra decena de soluciones que pueden combinarse y lograr una solución a la medida. De las tecnologías de código abierto recomendamos ELK.
Espero te guste y sea útil esta entrada.